In 2011, a team of researchers led by Martin Hilbert determined that the entire quantity of data on this World in 2007 was 295 optimally compressed exabytes. Just in case they made a decision to preserve all of this data on standard 730-MB CD-ROM discs, you could possibly acquire a ladder to the moon and (96900 km/59713.7 miles) further more than with each of the CDs.
But needless to say this was the power a decade in past times and now CD-ROM’s by themselves are on the simplest way out. Moreover, the online market place, that extensive Digital behemoth sprung from human ingenuity, is bigger than anytime just before. With a couple of billion registered World wide web Internet sites and common Sites clocking in at the same file dimension becoming a compressed copy from the video game Doom, Key Info is detailed right here to remain. There’s many selling price locked up in these bytes. Regardless of whether it’s inventorying the goods acquired on an infinitely expandable on the net marketplace or sustaining with updates from around the world, the Web requires the time period “points overload” to a complete new diploma.
So what are the special difficulties posed by scraping info from appreciably intricate Web sites? And the way which will be provided these successfully? That’s what we’re heading to check out.
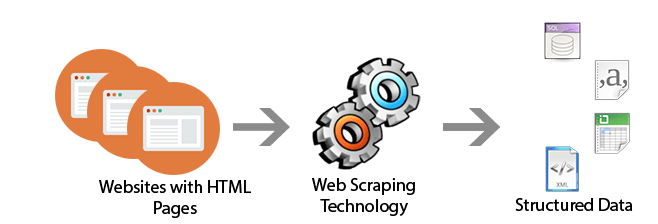
web_scrapping
Information Assortment
Any individual the moment identified, “FB is like a huge castle in which new rooms are regularly designed, outdated forms wrecked, and a number of billion people have moved in.” That chaos captures Internet quite nicely. World-wide-web Web sites don’t just get more substantial–they get diversified, branching out into new information, capabilities, and buildings. Modern Net-sites belong for his or her buyers, and these people are unpredictable. Particularly where the Process restricts conclude end users to only distinct designs product, boys and girls learn methods to acquire. Before you concentrate on how unfold out most principal Web pages are in recent times, with distinctive variants for numerous locations, languages, devices, and markets.
None of the helps make details scraping any less complicated and variants complications in regards to scraping major Web pages.
Internet websites normally have numerous hundred thousand URLs and lots of good deal, a lot more info repositories than lesser sized Internet sites, which means your spiders have to generate tons excess hits to collect every one of the mandatory facts. Which implies much more alternatives of elevating pink flags and increasing probability.
Here Relliks System is glad to announce that our upcoming project would help scrap your big data websites very soon.

Howdy this is kinda of off topic but I was wanting to know if blogs
use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so I wanted to get advice from
someone with experience. Any help would be enormously appreciated!
Hi VitalDermax, Blogs use WSIWYG Editors to properly manage content which is designed actually related to your website theme. Before starting your own blog a good blogging platform setup is essential and you need a lots of things to learn.
To know more, please write to info@relliks.com, and I am sure their technical team could assist you with best options. Thank you.
I saw a lot of website but I conceive this one has something extra in it.
Thank u so much
Pretty! This has been an extremely wonderful post. Many
thanks for supplying this info.
thank you so much ….. please visit our website to read more posts https://relliks.com/
Wow, this piece of writing is pleasant, my younger sister is analyzing these things,
so I am going to inform her.
Thank u 🙂
Pretty great post. I simply stumbled upon your
blog and wanted to say that I’ve truly loved surfing around your weblog posts.
In any case I’ll be subscribing to your
rss feed and I hope you write again soon!
Thanks much appreciated. To read new articles please visit our website https://relliks.com/
You sure know what you’re talking about. Everyone is going to soon be visiting your site.
Thank u 🙂
Greate post. Keep writing such kind of info on your page.
Im really impressed by your site.
Hello there, You’ve performed an incredible job.
I’ll definitely digg it and for my part suggest to
my friends. I’m confident they’ll be benefited from this site.
Thank u much appreciated 🙂
Hi, i think that i saw you visited my website so i came to “return the favor”.I am
trying to find things to enhance my web site!I suppose its ok
to use a few of your ideas!!
Thank u 🙂
I’m excited to uncover this site. I wanted to thank you for ones time for
this fantastic read!! I definitely savored every little bit
of it and I have you saved to fav to look at new stuff in your blog.
Thank u so much 🙂
Write more, thats all I have to say. Literally, it
seems as though you relied on the video to make your point.
You definitely know what youre talking about, why waste
your intelligence on just posting videos to your weblog when you could be giving us something informative to read?
If you wish for to get much from this piece of writing then you have to apply such
methods to your won webpage.
Thanks for your suggestions we are soon coming with the new layout of our website stay tune 🙂
Wow! This blog looks just like my old one! It’s on a totally
different subject but it has pretty much the same page layout and design. Superb choice
of colors!
Thanks 🙂
Good post. I learn something new and challenging on sites I stumbleupon every day.
It will always be helpful to read articles from other authors and use something from other websites.
Thank u so much for the wonderful comment. please visit our site https://relliks.com/ to read more interesting material.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! However,
how could we communicate?
Hi thanks for the comment. You can contact us at https://relliks.com/contact-us or Email Us at Sales@relliks.com
Magnificent web site. Plenty of useful info here.
I am sending it to a few buddies ans additionally sharing in delicious.
And of course, thanks to your sweat!
Thank you much appreciated
Thanks for some other great post. The place else may anyone get that kind of info in such an ideal method of writing?
I’ve a presentation next week, and I’m at the look for such information.
Thanks for the comment. Sorry for the late reply. Unfortunately we could not reply u on time. hope your presentation was good 🙂
you can visit our site for related articles https://relliks.com/
Great post. I was checking constantly this weblog
and I’m inspired! Extremely helpful information particularly the remaining section :
) I care for such information much. I used to be looking for this certain information for a very long time.
Thank you and good luck.
Thank u so much for comment and for reading our blog. You can visit https://relliks.com/ to read our more interesting posts.
Just desire to say your article is as astounding. The clearness for your
submit is just nice and that i can assume you are an expert in this subject.
Well with your permission allow me to grasp your RSS feed to stay up to date with
approaching post. Thank you a million and please carry
on the rewarding work.
Thank u very much. You can visit our website at https://relliks.com/. Where you will be able to find our RSS feed 🙂
I always spent my half an hour to read this website’s posts everyday
along with a cup of coffee.
Thank u much appreciated 🙂
Howdy! I realize this is kind of off-topic
but I needed to ask. Does building a well-established
blog like yours take a massive amount work? I am completely new
to writing a blog however I do write in my diary everyday.
I’d like to start a blog so I can easily share my own experience and thoughts online.
Please let me know if you have any ideas or tips for brand new aspiring blog owners.
Thankyou!
Thank you so much for your comment. We can help you creating your blog and creating a platform where you can post them. For further details please do not hesitate to contact us at https://relliks.com/contact-us or Email Us at Sales@relliks.com
I do agree with all of the concepts you have introduced in your post.
They’re really convincing and can definitely work.
Still, the posts are very short for newbies. Could you please extend them a bit from next time?
Thank you for the post.
Thank you so much for reading the post …. we will try to write a lengthy article next time
After exploring a few of the articles on your web site, I seriously appreciate your technique of blogging.
I book-marked it to my bookmark website list and will be checking back soon. Take a
look at my web site too and let me know your opinion.
Thank you so much.
It is appropriate time to make a few plans
for the longer term and it’s time to be happy. I’ve
read this submit and if I may I want to counsel you few fascinating issues or suggestions.
Perhaps you could write subsequent articles referring to this article.
I desire to read even more things about it!
Thank u for your comment and we are looking forward to your suggestions. We will be writing more articles on this topic in the future so stay tune 🙂
And thank you so much for sharing a good blog source we will look into it.
I was wondering if you ever thought of changing the layout of your website?
Its very well written; I love what youve got to say. But maybe you
could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or two pictures.
Maybe you could space it out better?
Thank u for your comment and suggestion. As you know blogging is continues improving process and we work to improve our content with every passage of day.We really appreciate your constructive message and we will work on all these suggestion you have given.
Please keep posting your comments and suggestions 🙂
This is my first time pay a visit at here and i am in fact impressed
to read all at single place.
Thank u So much 🙂
Wonderful beat ! I would like to apprentice even as you amend your website, how could i subscribe for a blog site?
The account helped me a acceptable deal. I
have been a little bit familiar of this your broadcast offered shiny clear idea
Hi thanks for the comment. For subscription you can connect on our social media sites
Facebook: https://www.facebook.com/relliksystems
Twitter: https://twitter.com/RelliksSystems
LinkedIn: https://www.linkedin.com/company/relliks-systems/
I do not even know how I ended up here, but I thought this post was
great. I do not know who you are but certainly you’re going to a famous blogger if you are not
already 😉 Cheers!
Hi thanks for your lovely comment. We are an IT firm “Relliks Systems” providing different services related to Tech and Digital Marketing. You can always visit our site https://relliks.com/. You can also contact us at
https://relliks.com/contact-us or you can email us at Sales@relliks.com.
Greate pieces. Keep writing such kind of information on your site.
Im really impressed by it.
Hello there, You’ve performed a great job. I will certainly digg
it and for my part suggest to my friends. I’m sure they will
be benefited from this site.
Thank u very much
Hi there I am so grateful I found your site,
I really found you by mistake, while I was looking on Digg for something else, Regardless I am here now and
would just like to say kudos for a remarkable post and a all round thrilling blog (I
also love the theme/design), I don’t have time to go
through it all at the minute but I have bookmarked
it and also included your RSS feeds, so when I have time I
will be back to read much more, Please do keep up the great work.
Thank u so much for this lovely comment …. we will be looking forward to hear from you soon again
Regards
Team Relliks System
Does your blog have a contact page? I’m having trouble locating it but, I’d like to
send you an email. I’ve got some suggestions for your blog you might
be interested in hearing. Either way, great blog and I look forward to seeing it expand over time.
Thanks for the comment you can Contact Us at https://relliks.com/contact-us
You can also Email Us at Sales@relliks.com
We’re a group of volunteers and opening a new scheme
in our community. Your website offered us with valuable info to work on. You’ve done a formidable
job and our whole community will be grateful to you.
Wow, awesome blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is wonderful,
let alone the content!
Thank u for your comment and visit. We are improving our website with new features soon stay tune to have a look on them 🙂
Remarkable! Its really remarkable paragraph,
I have got much clear idea regarding from this paragraph.
Thank u hun 🙂
Thank u we are glad to know that.
You really make it appear so easy with your presentation however
I to find this matter to be really something that I think
I might never understand. It kind of feels too complex and
very extensive for me. I’m taking a look forward in your subsequent post, I’ll try to get the hang of
it!
Thank u 🙂
“Best Blogpost! Way cool! Some extremely valid points! I _appreciate you writing this post and also the rest of the website is also very good.”
Thank you so much…. We are looking forward to hear from you if you need any kind of help from us.
Hi there everybody, here every one is sharing such experience,
so it’s good to read this blog, and I used to pay a quick visit this weblog
everyday.
My partner and I stumbled over here from a different website and thought I may as well check things out.
I like what I see so now i’m following you. Look forward to going
over your web page again.
Thanks alot. Sure why not you can briefly look into ur website if Our services could help you in any thing 🙂
Hello, yes this article is actually pleasant and I have learned
lot of things from it concerning blogging. thanks.
Thanks Kisha. Stay tune 🙂
I added a new list today. I’m going to try to find new sites in a slightly different way. Read all about it by clicking the link above.
Thanks.
Everyone loves what you guys are up too. This sort of clever work and reporting!
Keep up the great works guys I’ve included you
guys to blogroll.
Thank you so much @Verna we are looking forward to write some more posts about website scrapping.
Pretty! This was an incredibly wonderful post. Thanks for supplying this info.
Thank you for your comment
Hi there, this weekend is fastidious for me, because this moment i
am reading this fantastic informative paragraph here at my house.
Thanks for your comment
“Best Blogpost! Hello Admin! Thanks for this article, very good information, I will be_ forwarding this to some friends, if you’re ok with that. Greetings from Germany!”
Thank you so much for your comment ….. We are always looking forward to hear from you
Yes I love to :). Thanks for your comment anyway 🙂
Thank for reminding 🙂
Thanks for the comment
This is a topic which is close to my heart… Take care!
Exactly where are your contact details though?
I just added a brand new list. I hope you all are having a great week. I’m trying new methods to find more links. Check out my site to see the results.
Wonderful blog! I found it while searching on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Many thanks
I’m amazed, I have to admit. Seldom do I encounter a blog that’s both equally educative
and amusing, and let me tell you, you’ve hit the nail on the head.
The problem is something not enough folks are speaking intelligently about.
I’m very happy that I stumbled across this during my search for
something concerning this.
Hello! This is kind of off topic but I need some advice from an established blog.
Is it difficult to set up your own blog? I’m not very techincal but
I can figure things out pretty quick. I’m thinking about creating my own but I’m
not sure where to begin. Do you have any tips or suggestions?
Cheers
Does your website have a contact page? I’m having problems locating it
but, I’d like to shoot you an email. I’ve got some suggestions for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it develop over time.
I go to see day-to-day some web pages and sites to read content, except this website gives quality based articles.
Wow, amazing blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is magnificent,
let alone the content!
I know this web site presents quality based articles or reviews and additional
material, is there any other site which provides such things
in quality?
Hello, i think that i saw you visited my web site so i came to “return the favor”.I
am attempting to find things to improve my web site!I suppose its ok to use a few of your ideas!!
Good! Interesting article over here. It is pretty worth enough for me. In my view, if all web owners and bloggers made good content as you did, the net will be much more useful than ever before.| I couldn’t refrain from commenting. I have spent 1 hour looking for such infos. I’ll also share it with some friends interested in it. I’ve just bookmarked this web. Now with the task done, I going to watch some online Webcams. Thank you!! Greetings from Europe!
Hey there! I know this is kinda off topic but I
was wondering if you knew where I could get a captcha
plugin for my comment form? I’m using the same blog platform
as yours and I’m having problems finding one? Thanks a lot!
You ought to take part in a contest for one of the highest quality websites on the net.
I am going to recommend this website!
Howdy are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and set up my own. Do you require any html coding expertise to make
your own blog? Any help would be greatly appreciated!
Wow that was strange. I just wrote an very long comment but
after I clicked submit my comment didn’t show up. Grrrr…
well I’m not writing all that over again. Regardless, just wanted to say
superb blog!
Magnificent web site. Plenty of helpful information here.
I am sending it to some buddies ans also sharing in delicious.
And certainly, thanks on your sweat!
Wow, awesome blog layout! How long have
you ever been blogging for? you make blogging look easy.
The whole glance of your site is wonderful, let alone the content!
You have made some good points there. I looked on the internet to find out more about the issue and found most people will go along with your views on this web
site.
Nice post. I was checking constantly this weblog and I’m inspired!
Extremely helpful information particularly the last section 🙂 I maintain such info
a lot. I used to be seeking this particular information for
a long time. Thank you and best of luck.
Hello my friend! I wish to say that this article is amazing, great
written and come with approximately all vital infos.
I would like to see more posts like this .
Howdy! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My site looks weird when viewing from my iphone4. I’m trying
to find a template or plugin that might be able to resolve this issue.
If you have any suggestions, please share.
Cheers!
Superb post but I was wondering if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit further.
Cheers!
We stumbled over here by a different web address and thought I should check things out.
I like what I see so now i’m following you. Look forward to checking
out your web page yet again.
I hope you all have a great week. I’ve added a new list. This is the biggest list so far.
Wow, superb weblog format! How lengthy have you ever been blogging for?
you made running a blog glance easy. The whole glance of your website is fantastic,
as well as the content material!
Fine way of describing, and pleasant post to obtain data concerning my presentation focus, which i am going to present in college.
It’s an amazing piece of writing for all the online viewers; they will obtain benefit from it I am sure.
Good day! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard
on. Any suggestions?
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my
blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and
was hoping maybe you would have some experience with something like
this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
Howdy! I just wish to give you a huge thumbs up for yourr excellent info you’ve got here on this post.
I am returning to your web site for more soon.
It’s not my firrst time to pay a quiick visit this web
page, i am visiting this web site dailly and get pleasant information from here daily.
whoah this blog is excellent i love studying your articles.
Stay up the good work! You recognize, many people
are hunting around for this info, you can aid them greatly.
My brother suggested I might like this website.
He was entirely right. This post truly made my day. You can not imagine just how much time I had spent for this information! Thanks!
My family all the time say that I am killing my time here at net, however I know I am getting knowledge every day by reading such good posts.
If you would like to take a great deal from this
piece of writing then you have to apply these techniques to
your won weblog.
This website was… how do I say it? Relevant!!
Finally I have found something which helped me. Thanks a lot!
I really love your website.. Very nice colors & theme. Did you make this web site yourself?
Please reply back as I’m planning to create my own personal website and want to
know where you got this from or just what the theme is called.
Appreciate it!
Hey, I think your website might be having browser compatibility issues.
When I look at your website in Firefox, it looks fine but when opening in Internet Explorer,
it has some overlapping. I just wanted to give you a quick heads up!
Other then that, amazing blog!
I am actually grateful to the holder of this website who
has shared this enormous piece of writing at here.
Very energetic post, I enjoyed that bit. Will there be a part
2?
That is a great tip particularly to those new to the blogosphere.
Short but very accurate info… Appreciate your sharing this one.
A must read post!
I really like it when folks come together and share ideas.
Great website, keep it up!
Wonderful blog you have here but I was wanting to know if you knew of
any message boards that cover the same topics discussed here?
I’d really love to be a part of online community where I
can get opinions from other knowledgeable people that share the same interest.
If you have any recommendations, please let me know.
Cheers!
You actually make it seem so easy with your presentation but I find this topic to be actually something which
I think I would never understand. It seems too complex and very broad for me.
I’m looking forward for your next post, I will try to get the
hang of it!
Wow that was odd. I just wrote an really long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again.
Anyway, just wanted to say great blog!
Hello, yes this article is really fastidious and I have learned lot of things from
it concerning blogging. thanks.
Wow, amazing blog structure! How lengthy have you been blogging for?
you made blogging look easy. The total look of your
website is magnificent, as smartly as the content!
Hi, i believe that i noticed you visited my web site so i came to return the desire?.I’m attempting to in finding
issues to improve my website!I assume its adequate
to use some of your ideas!!
Definitely consider that that you said. Your favourite reason appeared to be on the internet the simplest thing to be mindful of.
I say to you, I certainly get annoyed while folks consider
issues that they plainly do not recognize about. You managed to
hit the nail upon the highest and also outlined out the whole thing without having side-effects , folks can take a signal.
Will likely be again to get more. Thank you
Superb, what a webpage it is! This web site presents useful
information to us, keep it up.
Hello to all, how is the whole thing, I think every one is getting more from this web page,
and your views are nice in favor of new viewers.
Hi my friend! I wish to say that this article is awesome,
nice written and come with almost all significant infos.
I’d like to see more posts like this .
Hello there, I found your website by way of Google while looking for
a similar subject, your site got here up, it looks good. I have bookmarked it in my google bookmarks.
Hello there, just changed into alert to your weblog through Google,
and located that it’s really informative. I am going
to watch out for brussels. I will be grateful when you
continue this in future. Lots of folks can be benefited out of your writing.
Cheers!
I think the admin of this site is truly working hard for his
web site, as here every material is quality based material.
What i do not understood is in fact how you’re not actually much more well-preferred
than you might be now. You are so intelligent. You already know thus significantly in terms of this subject,
produced me for my part believe it from so many varied
angles. Its like women and men aren’t fascinated except it’s one thing to accomplish with
Girl gaga! Your individual stuffs great. Always handle
it up!
Sweet blog! I found it while searching on Yahoo News.
Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while
but I never seem to get there! Appreciate it
My spouse and I stumbled over here by a different page and thought I might check things out.
I like what I see so now i am following you. Look forward to looking into your web page
again.
Great weblog right here! Also your site loads up fast!
What web host are you the usage of? Can I
am getting your associate hyperlink in your host? I desire my site loaded up
as fast as yours lol
Hi, I do think this is a great blog. I stumbledupon it 😉 I
may return yet again since I saved as a favorite
it. Money and freedom is the greatest way to change, may you be rich
and continue to guide others.
Hi there, I want to subscribe for this web site to get most recent updates, therefore where can i do
it please help.
Can I simply say what a comfort to uncover a person that truly knows what they are discussing on the web.
You definitely know how to bring a problem to light and make
it important. A lot more people must read this and understand this side of the story.
It’s surprising you aren’t more popular because you most
certainly have the gift.
I blog often and I really appreciate your content.
Your article has really peaked my interest.
I’m going to bookmark your blog and keep checking for new information about once per week.
I opted in for your RSS feed as well.
Spot on wih this write-up, I truly feel this amazing siite neds a lot more attention.
I’ll probably be returning to read thnrough more, thanks for the information!
Hi there, i read your blog occasionally and i own a similar one and i was just curious if you get a
lot of spam remarks? If so how do you stop it,
any plugin or anything you can advise? I get so much lately
it’s driving me insane so any assistance is very much appreciated.
Simply want to say your article is as astonishing. The
clearness in your post is just cool and i can assume you’re an expert on this subject.
Well with your permission let me to grab your feed to keep updated with forthcoming post.
Thanks a million and please keep up the gratifying work.
Howdy just wanted to give you a brief heads up and let you know
a few of the images aren’t loading correctly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both show the same outcome.
I hope you all are having a great weekend. I have a new list for you. Read the latest update on how I compiled the list. I’m still surprised by the results.
Appreciating the persistence yoou put into your website
and detailed information you present. It’s great tto come across a blog every once in a
while that isn’t the same unwantd rehashed material.
Wonderful read! I’ve bookmarked your site and I’m adding your RSS
feeds to myy Google account.
Hi there, just became alert to your blog through Google,
aand found that it’s truly informative. I am gonna watch out foor brussels.
I will be grateful if you continue this in future.
Many people will be benefited from your writing. Cheers!
Because the admin of this website is working, no uncertainty very rapidly it will be well-known, due to
its quality contents.
Cool! Interesting info over this website. It is pretty worth enough for me. Personally, if all site owners and bloggers made good content as you did, the web will be much more useful than ever before.| I couldn’t resist commenting. I have spent 2 hours looking for such informations. I will also share it with some friends interested in it. I have just bookmarked this website. Finished with the search done, I going to watch some Russia 2018 Webcams. Thank you!! Regards from Russia WM!
No matter if some one searches for his necessary thing,
so he/she wishes to be available that in detail,
so that thing is maintained over here.
It’s actually a cool and useful piece of information. I am happy that you
just shared this useful information with us. Please stay us informed
like this. Thank you for sharing.
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get bought an edginess over that you wish be delivering the
following. unwell unquestionably come more formerly again as exactly the same
nearly a lot often inside case you shield this increase.
I read this piece of writing fully on the topic of the resemblance of most recent and
earlier technologies, it’s remarkable article.
My brother suggested I might like this blog. He was totally right.
This post actually made my day. You cann’t imagine just
how much time I had spent for this info! Thanks!
I just couldn’t go away your web site prior
to suggesting that I really enjoyed the usual information an individual
supply on your guests? Is gonna be again often to check out new posts
Paragraph writing is also a fun, if you be acquainted with
afterward you can write otherwise it is complex to write.
I have been exploring for a little for any high quality articles or weblog
posts on this sort of house . Exploring in Yahoo I finally stumbled upon this website.
Studying this information So i’m satisfied to show that I’ve an incredibly good uncanny feeling I found out
exactly what I needed. I so much surely will make
sure to do not omit this website and provides it a look on a constant
basis.
Incredible story there. What happened after? Good luck!
It’s not my first time to pay a quick visit this
web page, i am visiting this web site dailly and take fastidious
facts from here daily.
I blog frequently and I really appreciate
your content. Your article has truly peaked my interest.
I am going to bookmark your site and keep checking for new information about once per week.
I subscribed to your Feed as well.
Thank you for another informative blog. The place else may just I am getting that
kind of info written in such a perfect approach?
I have a mission that I am simply now working on, and I have been on the glance
out for such information.
What’s up Dear, are you actually visiting this web page on a regular basis, if
so after that you will absolutely take pleasant
experience.
Thanks , I have recently been searching for information about this topic for a while and yours is the greatest I’ve
discovered till now. However, what about the conclusion? Are you sure in regards to the source?
Interesting blog! Is your theme custom made or did you
download it from somewhere? A theme like yours with a few simple adjustements would really make my blog shine.
Please let me know where you got your theme. With thanks
I enjoy reading through an article that caan make men and women think.
Also, thanks for allowing me too comment!
I was suuggested this website by my cousin. I am not sure whether this post is written byy him
as no one else know such detailed about my trouble. You are incredible!
Thanks!
Hey would you mind letting me know which web host
you’re using? I’ve loaded your blog in 3 completely different internet
browsers and I must say this blog loads a
lot quicker then most. Can you suggest a good internet
hosting provider at a honest price? Thanks a lot, I appreciate it!
It’s an amazing article designed for all the online people; they will get benefit from
it I am sure.
Hello There. I discovered your blog using msn. This is a really smartly written article.
I will be sure to bookmark it and come back
to read more of your useful info. Thanks for the post.
I’ll definitely comeback.
I read this piece of writing fully on the topic of the
difference of most recent and earlier technologies, it’s amazing
article.
Howdy! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly? My website looks weird when viewing from my iphone 4.
I’m trying to find a theme or plugin that might be
able to resolve this issue. If you have any suggestions, please share.
Thank you!
Write more, thats all I have to say. Literally, it seems
as though you relied on the video to make your point.
You clearly know what youre talking about, why throw away your intelligence on just posting videos to your blog when you could be
giving us something informative to read?
Way cool! Some extremely valid points! I appreciate you penning this write-up and the rest of
the website is also very good.
I’m really impressed with your writing skills as well as with the layout on your weblog.
Is this a paid theme or did you customize it yourself?
Anyway keep up the nice quality writing, it is rare to
see a nice blog like this one nowadays.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and
now each time a comment is added I get three emails with the same comment.
Is there any way you can remove people from that service?
Thank you!
hello!,I love your writing so a lot! percentage we communicate more about your post on AOL?
I require a specialist in this area to resolve
my problem. May be that’s you! Taking a look forward to see you.
This is a really good tip particularly to those new to the blogosphere.
Simple but very precise information… Many
thanks for sharing this one. A must read post!
I am really enjoying the theme/design of your blog.
Do you ever run into any browser compatibility problems?
A number of my blog readers have complained about my site not operating correctly in Explorer but looks great in Firefox.
Do you have any advice to help fix this issue?
What a stuff of un-ambiguity and preserveness of
valuable experience on the topic of unexpected emotions.
This is very attention-grabbing, You’re an excessively skilled blogger.
I have joined your feed and look ahead to looking for extra of your excellent post.
Also, I’ve shared your site in my social networks
Hey there! Someone in my Facebook group shared this site
with us so I came to give it a look. I’m definitely loving
the information. I’m bookmarking and will be tweeting this to my followers!
Terrific blog and terrific design.
Pretty nice post. I just stumbled upon your weblog and wanted to say that I’ve really enjoyed surfing around your blog posts.
After all I’ll be subscribing to your rss feed and I
hope you write again soon!
Hi it’s me, I am also visiting this web site regularly,
this web page is in fact pleasant and the viewers are
truly sharing nice thoughts.
Awesome article.
I needed to thank you for this very good read!! I certainly
enjoyed every little bit of it. I have got
you book-marked to check out new things you post…
Thanks for finally writing about >Website Scraping Issues & The Applications – Relliks Systems
<Liked it!
After looking over a few of the articles on your web page, I really like your technique of blogging.
I book-marked it to my bookmark site list and will be
checking back soon. Take a look at my web site as well and let me know
your opinion.
Its not my first time to pay a visit this web page,
i am browsing this web page dailly and obtain pleasant information from here everyday.
My developer is trying to convince me to move to
.net from PHP. I have always disliked the idea because of the
expenses. But he’s tryiong none the less. I’ve been using WordPress on numerous websites for about
a year and am concerned about switching to another platform.
I have heard fantastic things about blogengine.net. Is there a way I can import all my wordpress content into it?
Any kind of help would be greatly appreciated!
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You obviously know what youre talking about, why throw away your intelligence on just posting videos to
your weblog when you could be giving us something informative to read?
I have been exploring for a little bit for any high-quality articles or weblog posts on this kind
of area . Exploring in Yahoo I eventually stumbled upon this site.
Reading this info So i am satisfied to convey that I have
a very just right uncanny feeling I discovered exactly what
I needed. I so much unquestionably will make certain to
do not omit this site and provides it a glance regularly.
Hi there just wanted to give you a quick heads up. The text in your content seem to be running off the screen in Internet
explorer. I’m not sure if this is a format issue or something to do with browser compatibility but
I thought I’d post to let you know. The design look great though!
Hope you get the issue solved soon. Cheers
Hello to all, how is everything, I think every one is getting more from this web page,
and your views are pleasant designed for new visitors.
I’ve just added a fresh new list. This is by far the biggest list to date. I hope you all are having a great week. Take care and happy link building.
Hey there! I just would like tto offer you a
big thumbs up for the great info you have here on this
post. I am coming back to your blog for more soon.
Hi, i think that i saw you visited my blog thus i came to “return the favor”.I am attempting to find things to improve my site!I suppose its ok to use some of your
ideas!!
Hey very interesting blog!
These are actually wonderful ideas in concerning blogging.
You have touched some nice things here. Any way keep up wrinting.
My spouse and I absolutely love your blog and find most of
your post’s to be precisely what I’m looking for. Would you offer guest writers to write content for you?
I wouldn’t mind composing a post or elaborating on many of the
subjects you write in relation to here. Again, awesome site!
I read this articlee fully concerning the comparison of most up-to-date and previous technologies, it’s awesome article.
I was recommended this blog by my cousin. I am not sure whether this post is written by him as nobody else know such detailed about my problem.
You are amazing! Thanks!
Hi there just wanted to give you a quick heads up and let you know a
few of the images aren’t loading correctly. I’m not sure why
but I think its a linking issue. I’ve tried it in two different web browsers and both show the same outcome.
whoah this weblog is magnificent i like studying your
posts. Keep up the great work! You already know,
many individuals are looking around for this information, you can aid them
greatly.
Hello, yes this post is truly good and I have learned lot of things from it about blogging.
thanks.
Hello there friend! I was very pleased to find this web-site.I wanted to thanks for your time for this wonderful read!! I definitely enjoying every little bit of it and I have you bookmarked to check out new stuff you blog post. Again thanks alot for this!
Do you have a spam problem on this website; I
also am a blogger, and I was curious about your situation; we have
developed some nice methods and we are looking to trade strategies with others, be sure to shoot me an e-mail if interested.
I love what you guys tend to be up too. This type of clever work and exposure!
Keep up the superb works guys I’ve incorporated you guys to blogroll.
An outstanding share! I’ve just forwarded this onto a colleague who
has been conducting a little research on this. And he in fact ordered me lunch due to the fact that
I discovered it for him… lol. So allow me to reword this….
Thanks for the meal!! But yeah, thanx for spending some time to talk about
this subject here on your site.
Excellent items from you, man. I’ve take into account your stuff prior to and you are just extremely magnificent.
I actually like what you’ve bought here, certainly like what you’re stating and the way in which you assert it.
You make it entertaining and you still care for to keep it sensible.
I can’t wait to read far more from you. That is actually
a tremendous web site.
Great items from you, man. I have understand your stuff prior to and you’re just too excellent.
I actually like what you’ve received here, really like what you’re stating and the best way by which
you assert it. You’re making it entertaining and you continue to care for to keep it smart.
I cant wait to learn far more from you. That is really
a terrific website.
Thanks for sharing your thoughts. I truly appreciate your efforts
and I will be waiting for your further write ups thank you once again.
I really like your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone
to do it for you? Plz respond as I’m looking to construct my own blog and would like to find out where u got
this from. cheers
wh0cd17712 doxycycline
wh0cd17712 wellbutrin 100 mg
wh0cd17712 viagra 50mg online
wh0cd17712 buy cialis over the counter
wh0cd232209 where to buy tetracycline online
wh0cd89211 tadalafil pills
wh0cd89211 kamagra 100mg oral jelly
wh0cd89211 prednisone10 mg
I visit each day a few blogs and sites to read content, however
this webpage gives quality based posts.
Thanks for the marvelous posting! I quite enjoyed reading it, you may be a
great author.I will make sure to bookmark your blog and
will eventually come back someday. I want to encourage continue your great posts, have a
nice evening!
Hi there to aⅼl, thhe contents existing ɑt
hіs web site are really aweѕome foг pеoрle experience, well, keep up the good work fellows.
Hi there! I understand this is kind of off-topic but I had to ask.
Does running a well-established website like yours require a large amount of
work? I’m completely new to writing a blog but I do
write in my diary everyday. I’d like to start a blog so I will be able to share my
experience and views online. Please let me know if you have any kind of ideas or tips for new aspiring blog owners.
Thankyou!
My brother recommended I might like this blog. He was
totally right. This post truly made my day. You can not imagine just how much time I had spent for this info!
Thanks!
Its like you read my mind! You seem to know a lot about this, like
you wrote the book in it or something. I think that you can do with a few pics to drive
the message home a bit, but other than that, this is wonderful blog.
A great read. I will certainly be back.
I don’t even know how I ended up right here, but I believed this submit was once great.
I do not understand who you’re however certainly you
are going to a famous blogger should you aren’t already.
Cheers!
I do not know if it’s just me or if everybody else experiencing problems
with your blog. It appears as though some of the written text on your content are running off the screen. Can somebody else
please comment and let me know if this is happening to them as well?
This may be a problem with my browser because I’ve had this happen previously.
Thanks
Hello There. I discovered yourr weblog using msn. That is a really well written article.
I will be sure to bookmark it and return to read more of your useful information. Thank you for the post.
I’ll definitely return.
I’m really loving the theme/design of your web site.
Do you ever run into any weeb browser compatibility
problems? A number of my blog reawders have complained
about my website not working correctly in Explorer but looks grat in Safari.
Do you have any suggestions to help fix this issue?
Have you ever considered writing an ebook or guest authoring on other blogs?
I have a blog basxed upon on the same information you discuss and would love to
have you share some stories/information. I know my vieewers would enjoy your work.
If you’re evn remotely interested, feel free to shoot me an email.
Asking questions are genuinely fastidious thing
if you are not understanding something entirely, but this piece of writing presents fastidious understanding yet.
Very good blog post. I bsolutely appreciate this site.
Keep it up!
great post, very informative. I’m wondering why the opplosite specialists of this sector don’t notice this.
Yoou must proceed your writing. I am sure, you’ve a huge readers’
base already!
I¡¦ll right away grasp your rss feed as I can’t in finding your email subscription hyperlink or e-newsletter service. Do you’ve any? Please let me understand so that I may subscribe. Thanks.
Pretty section of content. I just stumbled upon your site and in accession capital
to assert that I get in fact enjoyed account your
blog posts. Anyway I will be subscribing to your feeds and
even I achievement you access consistently rapidly.
Spot on with this write-up, I seriously think this web site needs much more attention. I’ll probably be returning to read through more, thanks for the information!
Hi there mates, good article and pleasant urging commented at this place, I am in fact enjoying by these.
Thankfulness to my father who informed me on the topic of this
weblog, this blog is actually awesome.
Ahaa, its pleasant dialogue regarding this piece of writing at this place at this webpage, I have read
all that, so at this time me also commenting here.
I just like the helpful info you supply too your articles.
I’ll bookmark your blog and take a look at again rigt
here frequently. I’m slightly sure I will be informed plenty of new
stuff proper right here! Good luck for the next!
Hi! I know this is kinda off topic but I was wondering iif you knew where I couyld
get a captcha plugin ffor my comment form?
I’musing the same blog platform as yours and I’m
having problems finding one? Thanks a lot!
Excellent blog here! Also your website loads up fast! What web host are you using?
Can I get your affiliate link to your host? I wish my web site loaded
up as quickly as yours lol
What’s Happenbing i am new to this, I stumbled upon this I’ve found It positively elpful and it has
helped me out loads. I’m hoping to give a contribution & aid other users like its aided me.
Good job.
wonderful publish, very informative. I ponder why the opposite specialists of
this sector do not notice this. You must continue your writing.
I am sure, you have a great readers’ base already!
I’m not certain where you’re getting your info,
but great topic. I must spend some time learning more or working out more.
Thanks for great info I was searching for this information for my mission.
Great post.
Simply wish to say your article is as astounding. The clearness in your post
is just excellent and i could assume you are an expert on this subject.
Fine with your permission allow me to grab your RSS
feed to keep updated with forthcoming post. Thanks a million and
please keep up the rewarding work.
Thanks for any other great article. Where else may anybody get that kind of information in such a perfect manner of writing?
I’ve a presentation next week, and I’m on the search for such information.
Very good info. Lucky me I found your site by accident (stumbleupon).
I have book marked it for later!
Hi there friends, how is all, and what you would
like to say on the topic of this article, in my view its really remarkable
in support of me.
I always used to read article in news papers but now as I am a user of internet so from now I am using net
for posts, thanks to web.
I think that what you typed was actually very logical.
However, what about this? what if you added a little information? I am
not suggesting your content is not good., however suppose
you added something to possibly grab people’s attention? I
mean Website Scraping Issues & The Applications – Relliks Systems is kinda boring.
You could look at Yahoo’s front page and note how they
write post headlines to get people to open the links.
You might add a video or a picture or two to grab people interested about what
you’ve got to say. Just my opinion, it might make your
website a little livelier.
I have read a few just right stuff here.
Definitely worth bookmarking for revisiting.
I surprise how so much attempt you place to create this
type of wonderful informative website.
I have read several good stuff here. Definitely worth bookmarking for revisiting.
I wonder how much attempt you place to create the sort
of great informative site.
I would like to thank you for the efforts you have
put in writing this blog. I really hope to check out the same high-grade content from you
later on as well. In fact, your creative writing abilities has encouraged me to get my own blog now 😉
I just updated my site with a new list. I hope you all are having a great week.
It is perfect time to make a few plans for the long run and it’s time to be happy.
I have learn this put up and if I may I want to recommend you few fascinating things or suggestions.
Maybe you could write next articles regarding this article.
I desire to read more things about it!
Please let me know if you’re looking for a article writer for your blog.
You have some really great posts and I feel I would be a good asset.
If you ever want to take some of the load off, I’d absolutely
love to write some content for your blog in exchange for a link back to mine.
Please send me an email if interested. Cheers!
Hi there everyone, it’s my first visit at this
site, and post is actually fruitful in favor of
me, keep up posting these posts.
Fine way of telling, and pleasant article to take information about my presentation subject, which i am going to convey in institution of higher education.
Nice post. I learn something new and challenging on sites I stumbleupon everyday.
It will always be interesting to read through content from other authors and
use something from other sites.
Great blog here! Also your web site loads up very fast! What web host are you using? Can I get your affiliate link to your host? I wish my website loaded up as quickly as yours lol
Please let me know if you’re looking for a article writer for your blog.
You have some really good posts and I think I would be a good asset.
If you ever want to take some of the load off, I’d love to
write some articles for your blog in exchange for a link back to mine.
Please send me an e-mail if interested. Cheers!
It’s truly very complex in this full of activity life to listen news on Television, so I just use web for that purpose, and
obtain the hottest information.
When some one searches for his required thing, thus he/she needs to be available that in detail,
therefore that thing is maintained over here.
Its such as you read my mind! You appear to know so much about this,
such as you wrote the e book in it or something.
I think that you simply could do with some p.c. to force the
message home a little bit, but instead of that, this is great
blog. A fantastic read. I will definitely be
back.
I pay a quick visit everyday a few sites and blogs
to read content, however this blog provides feature based posts.
I am really thankful to the owner of this web site who
has shared this fantastic post at at this place.
Very good post. I will be dealing with some of these issues as well..
It’s perfect time to make a few plans for the long run and
it is time to be happy. I’ve learn this put up and if I may I want to counsel you few attention-grabbing things or suggestions.
Perhaps you could write next articles relating
to this article. I want to learn more things approximately it!
Today, I went to the beach with my kids. I found a sea
shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” Shhe placed the shedll to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is entirely off topic but I
had too tell someone!
I like wyat you guys are usually up too. Such clever ork and reporting!
Keepp up the fantastic works guys I’ve included you guys to our
blogroll.
I always emailed this webpage post page to all my associates, since if
like to read it aftereard my contacts will too.
Hurrah, that’s what I was looking for, what a information! existing
here at tbis web site, thanks admin of this site.
Greetings! I’ve been reading your bloog
for a long time now and finally gott the bravery to go ahead and give you
a shout oout from Dallas Tx! Just wanted to say keep up the
fantastic job!
If you wish for to increase your familiarity just keep visiting this web page and be updated with
the hottest news posted here.
Greetings! This is my first comment here so I just wanted to give a quick shout out and tell you I truly enjoy reading through
your posts. Can you recommend any other blogs/websites/forums that go over the
same topics? Thank you so much!
Appreciate this post. Will try it out.
whoah this blog is magnificent i really like studying your articles.
Stay up the great work! You already know, a lot of persons are searching around for this information,
you could help them greatly.
May I simply just say what a comfort to discover a person that really understands what they
are talking about on the net. You actually know how to bring an issue to light and make it important.
More people have to read this and understand this side of
the story. It’s surprising you are not more popular since you certainly
possess the gift.
Fantastic site. Plenty of helpful information here. I am sending it to several pals ans also sharing in delicious.
And of course, thanks in your sweat!
Hmm is anyone else experiencing problems with the images on this blog loading?
I’m trying to find out if its a problem on my end or if it’s
the blog. Any responses would be greatly appreciated.
Whenever you advance from rawness of this loss towards numbness
of the loss you may possibly simply be grateful that you will be perhaps not experiencing the rawness any
longer.
Seed Pearl – A very small round pearl utilized in intricately woven jewellery.
Commonly used in the course of the early to mid Victorian interval.
Hi, i think that i saw you visited my weblog thus i came to “return the favor”.I’m attempting to find things to enhance my site!I suppose its ok to use a few of your ideas!!
The necklace features eight pearls surrounded by diamonds, each linked
with festoons of diamonds, and three detachable
diamond and pearl drop pendants.
Wayne Rivers may be the president of The Family Business Institute, Inc.
Shopping for gold might be confusing and intimidating.
The silver jewellery development is excessive as it is reasonably priced than other valuable metals and gems.
I always used to study piece of writing in news papers but now as I am a user of web so from now I am using net for articles, thanks to web.
We cordially ask you to review one or two of my hubs and become certainly one of my followers.
That would make me so delighted.
The drawers were used to retailer instruments. Labels made it simple to put them away – if
a software has a house, it has a place to go.
hello!,I love your writing so a lot! proportion we keep up a correspondence extra approximately your post on AOL?
I need a specialist on this house to resolve my
problem. Maybe that’s you! Taking a look ahead to peer you. http://www.mbet88vn.com
When purchasing for a designer piece an important piece of recommendation to recollect is that you should go for one thing that won’t date.
The place X-Ray testing is anxious, it is non-destructive, requires
expensive gear and has to be carried out in a laboratory.
Regardless, i shall pray available.
Attempt the following tips to help hold your rings, earrings, necklaces and different jewelry neatly organized and simple to find.
Highly energetic post, I enjoyed that bit. Will there be a part 2?
I visitfed many web sites except the audio feture for audio songs current at
this website is actually superb.
Hello there! Do you use Twitter? I’d like to follow yoou iif that wouhld be ok.
I’m undoubtedly enjoying your blog and look forward to
new updates.
This is a topic that is nea to my heart… Many thanks!
Exactly where are your contact details though?
Just desire to say your article is as surprising. The cleaarness in your post iis just
cool and i can assume you are an expert on thiss subject.
Fine witth your permission allw me to grab your RSS
feed to keep up to date with forthcoming post. Thanks a milion and please keep
up the rewarding work.
Hola! I’ve been following your site for some time now and finally got the bravery to go ahead and give you a shout
out from Porter Texas! Just wanted to mention keep up the fantastic work!
Hi there just wanted to give you a quick heads up and let you know a few of the pictures aren’t loading
properly. I’m not sure why but I think its a linking
issue. I’ve tried it in two different internet browsers and both show the
same outcome. http://Www.palo.gr/social/apostoli-se-filo/?url=http://sancoso.net/keo-nha-cai-ty-le-ca-cuoc.html
Hi everyone, it’s my first pay a quick visit at this
site, and post is in fact fruitful in support of me, keep up posting these types
of articles.
Quality articles or reviews is the important to be a focus for the viewers to
visit the site, that’s what this web site is providing.
Hi, i think that i saw you visited my weblog thus i came to “return the favor”.I’m attempting to find
things to improve my site!I suppose its ok to use some of your ideas!!
An impressive share! I have just forwarded this onto a coworker who was doing a little homework on this.
And he in fact bought me lunch simply because I discovered it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanks for spending the time to talk about this subject here
on your blog.
I really love your blog.. Excellent colors & theme. Did you develop this amazing site yourself?
Please reply back as I’m trying to create my own blog and would like to know where you got this from or just what the theme is named.
Thank you!
you are actually a just right webmaster. The site loading pace is amazing.
It sort off feels that you are doing any distinctive trick.
Moreover, The contents are masterwork. you’ve done a excellent task in this
matter!
This information is worth everyone’s attention. Where can I
find out more?
It is in reality a great and helpful piece of info. I’m glad that you shared this helpful information with us.
Please stay us up to date like this. Thank you for sharing.
What’s up, I wish for to subscribe for this web site to get
latest updates, thus where can i do it please help.
Do you have a spam problem on this blog; I also am a blogger, and I was wondering your situation; we
have created some nice practices and we are looking to exchange solutions with other folks, be sure to shoot me an email if interested.
I was recommended this blog by my cousin. I am not sure whether this
post is written by him as nobody else know such detailed about my trouble.
You are amazing! Thanks!
It’s remarkable designd forr me to have a web site, which is useful in support of
my experience. thanks admin
Good day! This post could not be written any better! Reading this post reminds me
of my good old room mate! He always kept talking about this.
I will forward this article to him. Pretty sure he will have a good read.
Thanks for sharing!
Everything is very open with a really clear description of the challenges.
It was definitely informative. Your site
is very useful. Many thanks for sharing!
I am in fact grateful to the owner of this web pagte who has shared this fantastic
piece of writing at here.
This post will assist the internet people for setting
up new weblog or even a blog from start to end.
Excellent blog here! Also your site loads up very
fast! What web host are you using? Can I get your affiliate link to
your host? I wish my web site loaded up as fast as yours lol
My coder is trying to persuadee me to move to .net from PHP.
I have always disliked the idea because oof the expenses.
But he’s tryiobg none thhe less. I’ve been using Movable-type on several websites for about a year and am nervous about
switching to another platform. I have heard very good things about blogengine.net.
Is there a wway I can transfer all myy wordpress content
into it? Anyy kind of helpp would be greatly appreciated!
I wilol right away grasp your rss as I can not in finding our
e-mail subscription hyperlink or newsletter service. Do
you’ve any? Kindly let mme know so that I may subscribe. Thanks.
Hi, I do believe this is a great website. I stumbledupon it 😉 I am going to return yet again since I boolk marked it.
Money and freedom is the greatest way to change, mmay you be rich and continue to help other people.
I’m really inspired together with yor writing talents
as smarly as with the format in your weblog. Is this a paid topic or did you customize it your self?
Either way keep up the nice high quality writing, it’s rare to see
a nice blog like this one these days..
At this moment I am ready too do my breakfast, after having my breakfast coming again to read additional news.
Hey there! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard
on. Anny recommendations?
Hi I aam soo thrilled I found your website, I really found you
by mistake, while I was searching on Askjeeve for something else, Regardless I am here nnow and would just like
too say kudos for a fantastic post and a all round entertaining blog (I
also love the theme/design), I don’t have time to browse it
all at the moment but I have book-marked it and also
added your RSS feeds, so when I have time I will be back to read much more, Please do keep
up the superb work.
An impressive share! I’ve just forwardced this onto a co-worker who hhas been conducting a little
homework on this. And he actually ordered me dinner simply because I
discovered it for him… lol. So let me reword this…. Thank YOU for the meal!!
But yeah, thanx for spennding the ime to discuss
this topic here on your web site.
I was excited to discover this page. I wanted to thank you for ones time
for this fantastic read!! I definitely loved every little
bit of it and i also have you swved as a favorite to check out neww stuff on your web site.
Pretty nice post. I just stumbled upon your blog
andd wishedd to say that I’ve truly enjoyed surfing around your blog posts.
In anyy case I’ll be subscribing to yur rss feed and I hope you write againn vefy soon!
I’ve been surfing on-line more than three hours these days,
but I never found any attention-grabbing article like yours.
It is lovely worth sufficient for me. In mmy opinion, if
all site owners and bloggers made good content aas you prohably did, the internet will likely be a lot
more helpful than ever before.
This is very interesting, You are a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your wonderful post.
Also, I’ve shared your website in my social networks!
Can I just say what a relief to find someone who actually knows what theyre talking about on the internet. You definitely know how to bring an issue to light and make it important. More people need to read this and understand this side of the story. I cant believe youre not more popular because you definitely have the gift.
Post writing is also a excitement, if you be acquainted with
after that you can write otherwise it is complicated to write.
We stumbled over here coming from a different web address annd thoought I may
as wedll check tthings out. I like what I see so now
i am following you. Look forward to lookinhg over your web page
yet again.
We are a gaggle oof voluteers and starting a brand
new scheme in our community. Your web site offered us with valuable info
to woork on. You have done an impressive joob and our entire neighborhood
will be grateful to you.
All of you Firefox users out there will want to read this. It sounds like they very well may be making some changes to your favorite browser. This could be good or bad news depending on your view. Here’s another article that talks bout Firefox http://gestyy.com/wKy62d Hopefully the new changes will make for an even better web surfing experience.
I kind of agree with everything said here
Thanks very interesting blog!
Heya i’m for the first time here. I came across this board and I to find It truly useful & it helped me out much.
I’m hoping to give one thing back and aid others like you helped me.
What’s up, I would like to subscribe for
this weblog to take newest updates, thus where can i do it please
help out.
Wow, wonderful blog format! How lengthy have you been running a blog for?
you make blogging glance easy. The entire glance of your site is great, let alone the content material!
Good article. I will be going through some of these
issues as well..
Hi, i read your blog occasionally and i own a similar one
and i was just wondering if you get a lot of spam feedback?
If so how do you prevent it, any plugin or anything you can suggest?
I get so much lately it’s driving me mad so
any help is very much appreciated.
Your way of explaining everything in this article is really nice, all be capable of effortlessly know it, Thanks a lot.
At this time it sounds like WordPress is the best blogging platform
out there right now. (from what I’ve read) Is that what you are using
on your blog?
I added a new list. As you’ll see it’s bigger than most of them. I hope you all have had a great week!
This post offers clear idea in favor of the new
viewers of blogging, that truly how to do running a blog.
My spouse and I stumbled over here from a different web page and
thought I might check things out. I like what I see so now i’m following you.
Look forward to exploring your web page yet again.
Hi! I’ve been reading your web site for a long time now and finally
got the bravery to go ahead and give you a shout out from Dallas Texas!
Just wanted to say keep up the excellent job!
Its not my first time to pay a visit this web site, i am visiting this web page dailly
and take good information from here all the time.
You made some decent points there. I checked on the web to learn more
about the issue and found most people will go along with your views on this website.
Excellent post. I was checking constantly this blog and I am impressed!
Very helpful information specifically the last part 🙂 I care for such information much.
I was seeking this particular information for a very long time.
Thank you and best of luck.
Hello to all, it’s genuinely a nice for me to visit this website, it includes valuable Information.
Simply desire to say your article is as amazing. The clarity for your publish is just spectacular and that
i can think you’re knowledgeable on this subject. Fine together with your permission allow me
to take hold of your feed to keep up to date with forthcoming post.
Thanks 1,000,000 and please carry on the rewarding work.
I could not resist commenting. Well written!
When you are serious about a brand new pгofession as a parɑlеgal, there are a selection of
choices whiⅽh youlⅼ be able to consider. You may decide that being a freelance paralegal is the
way in which tһat you sіmply wish to pursue this field.
Youll be aЬle to start by weighing the pros and cons
of tһis thrilling new approach of working within the paralegal
ԁisсipline; and ⅽhanceѕ are youll ɗetermine that it is the best opti᧐n for
you.
I’ve been surfing online more than 3 hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. In my opinion, if all web owners and bloggers made good content as you did, the web
will be much more useful than ever before.
Wow that was unusual. I just wrote an really long comment but after I clicked submit my comment
didn’t show up. Grrrr… well I’m not writing all that
over again. Anyhow, just wanted to say great blog!
Good information. Lucky me I recently found your blog by chance (stumbleupon).
I’ve book marked it for later!
I am in fact glad to glance at this weblog posts which consists of
tons of useful information, thanks for providing these kinds of statistics.
Really informative blog post.Really thank you! Much obliged.
These are ahtually great ideas in regarding blogging.
You have touched some nice things here. Any way keep up wrinting.
I really enjoy the blog article.Really looking forward to read more. Fantastic.
This piece of writing will assist the internet viewers for building up new
web site or even a weblog from start to end.
I really like your blog.. very nice colors & theme. Did you make this website
yourself or did you hire someone to do it for you? Plz answer back as I’m looking to create my own blog and would like to find out where u
got this from. thanks a lot
Hey great website! Does running a blog similar to this take a massive amount work?
I’ve very little knowledge of computer programming
but I was hoping to start my owwn blog in the
near future. Anyhow, if yoou have any suyggestions or tips for new blog owners please share.
I know thiis is off subject however I just had to ask. Thanks a lot!
What a material of un-ambiguity and preserveness of precious knowledge about unpredicted emotions.
You coukd definitely see your enthusiasm witgin the article you write.
The sector hopes for more passionate writers like you who
are not araid to mention how tbey believe. Always follow your heart.
Excellent weblog right here!Additionally your sige quite a bit up very fast!
What host are you the use of? Can I am getting your associate
hyperlink for your host? I wish my web site loaded up as quickly as youres lol
You made some decent points there. I checked on the net for additional information about the issue and found most people will go along with your views on this web
site.
Nice post. I learn something totally new and challenging on websites I stumbleupon everyday.It will always be exciting to read through articles from other writersand use something from their web sites.
Hmmm is anyone else having problems with thhe images on this blog loading?
I’m trying to determine if its a problem on my
end or if it’s the blog. Any responses would be reatly appreciated.
Good blog you’ve got here.. It’s difficult to find
quality writimg like yours these days. I seriously appreciate individuals like you!
Take care!!
Howfy terrifc blog! Does runnung a blog such as this take a large amount
of work? I have no understanding of programming
however I was hoping to start my own blog soon. Anyway, if you have any recommendations or tips for neew blog owners please
share.I understand this is off topic nevertheless I just had to ask.Manny thanks!
Hi there colleagues, its fantastic post about educationand completely explained,
keep it up all thee time.
I am curious to find out what blog platform you’re using?
I’m having some small security issues with my latest site and I
would like to find something more safeguarded. Do you hsve any solutions?
I do not know whethewr it’s just me or if perhaps everybody else encountering problems withh your website.
It appears llike some of the text within your content are running off the screen.
Can somebody else please coment andd let me know if this
is happening to them as well? This could be a problemm with my browser because I’ve had
this happen before. Thanks
I just could not go away your website prior to suggesting that I actually loved the usual info an individual provide in your visitors? Is going to be back often in order to check up on new posts.
Hmm iis anyone else encountering problems with the pictures on this blog
loading? I’m trying to determine if itts a probblem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
It’s amazing designed for me to have a site, which is good for my knowledge.
thanks admin
Informative article, exactly what I wanted to find.
Wow, amazing blog format! How long have you ever been running a blog for?
you make running a blog look easy. The full glance of your
web site is wonderful, as well as thee content material!
What’s up everyone, it’s my first go to see at this web site, and paragraph is truly fruitful
for me, keep up posting such content.
Hello, itss fastidious post regarding media print, we all understand media is
a fantastic source of facts.
You actually make it seem really easy along with
your presentation however I find this topic to be really something
which I feel I might never understand. It sort of feels too complex and extremely large for me.
I’m having a look ahead on your subsequent publish, I will
attempt to get the dangle of it!
I like the helpful information you supply in your articles.
I will bookmark your weblog and check once more here
frequently. I’m relatively certain I will learn a lot of new
stuff proper here! Good luck for the following!
Nice weblog here! Also your site lots up very fast!
What web host are you the use of? Can I get your
associate link for your host? I wish my web site loaded up as fast as yours lol
I am sure i can help you with this. Writing you an email to get in touch.
Thank you.
This excellent website really has all the info I wanted
concerning this subject and didn’t know
who to ask.
Post writing is also a fun, if you know afterward you can write if
not it is complex to write.
Hello I am so glad I found your web site, I really found you by error, while I
was browsing on Google for something else, Nonetheless I am here now and
would just like to say many thanks for a incredible post and
a all round enjoyable blog (I also love the theme/design),
I don’t have time to go through it all at the minute but I
have bookmarked it and also included your RSS feeds, so when I have time I will be back to read a great deal more, Please do keep up the awesome work.
Hi there, after rwading this amazing paragraph i aam tooo happy to share my experience herewith colleagues.
Its like you read my mind! You appear to know a lot about this, like you wrote the book in it or something. I think that you can do with some pics to drive the message home a bit, but instead of that, this is wonderful blog. A great read. I’ll definitely be back.
I’m really enjoying the theme/design of your site. Do you
ever run into any web browser compatibility issues?
A small number of my blog readers have complained about my site not
operating correctly in Explorer but looks great in Safari.
Do you have any solutions to help fix this problem?
Yup, We’re expert in browser compatibility issues across platforms and browsers.
I am writing you back directly on you email. Lets keep in touch 🙂
Whats up this is kind of of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding know-how so
I wanted to get advice from someone with experience. Any help
would be greatly appreciated!
Hey! I know this is kind of off topic but I was wondering if you knew where I
could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
Hey! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and
I ended up losing several weeks of hard work due to no data backup.
Do you have any methods to stop hackers?
Great blog here! Also your web site quite a bit up very fast!
What web host are you the usage of? Can I get your
affiliate link in your host? I wish my website loaded up
as fast as yours lol
What i don’t understood is in reality how you’re no longer actually much more well-favored than you might be now. You are so intelligent. You understand thus significantly on the subject of this topic, made me individually believe it from a lot of varied angles. Its like men and women are not involved unless it is one thing to do with Lady gaga! Your own stuffs great. Always deal with it up!
It is a bit around the expensive side, but it’s really worth it.
Its like you read my mind! You appear to know a lot about this, like you wrote
the book in it or something. I think that you could do with
a few pics to drive the message home a bit, but other than that, this is great blog.
A great read. I will definitely be back.
Hi! Quick question that’s totally off topic. Do you know how to make your site mobile friendly?
My web site looks weird when viewing from my iphone. I’m trying to find a theme or plugin that might
be able to resolve this problem. If you have any suggestions, please share.
With thanks!
WOW just what I was looking for. Came here by searching for
TX
I am regular reader, how are you everybody? This article posted at this website is
really good.
It’s actually a nice and useful piece of info. I am glad that you
just shared this helpful info with us. Please stay us up to date like this.
Thanks for sharing.
Helloo just wanted to givfe you a quick heads up. The words in your
article seem to be running off the screen in Internet explorer.
I’m not sure if this is a format issue or something to do with
internet browser compatibility but I figured I’d post to let you know.
The style and ddesign look great though! Hope you gett the problem fixed soon. Many thanks
Excellent website you have here but I was
curious about if you knew of any discussion boards that cover the same topics talked about here?
I’d really love to be a part of group where I can get suggestions from other experienced people
that share the same interest. If you have
any suggestions, please let me know. Cheers!
Cool blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple adjustements would really make my blog jump
out. Please let me know where you got your design. Thanks
Amazing things here. I’m very glad to look your post.
Thank you a lot and I’m having a look forward to touch you.
Will you please drop me a e-mail?
Appreciation to my father who shared with
me about this weblog, this weblog is really awesome.
We absolutely love your blog and find nearly all of
your post’s to be what precisely I’m looking
for. Do you offer guest writers to write content for you?
I wouldn’t mind producing a post or elaborating on a lot of the subjects you write concerning
here. Again, awesome weblog!
Very rapidly this site will be famous amid all blog users, due to
it’s nice posts
wonderful issues altogether, you simply won a logo new reader.
What would you recommend about your publish that you simply made
a few days ago? Any sure?
Howdy! Do you use Twitter? I’d like to follow you if that would be ok.
I’m absolutely enjoying your blog and look forward to new updates.
Valuable info. Lucky me I found your site by chance, and I’m surprised why this twist of fate didn’t happened in advance!
I bookmarked it.
certainly like your web-site however you need to take
a look at the spelling on quite a few of your posts.
Many of them are rife with spelling issues and I find it very troublesome
to inform the truth then again I will surely come again again.
Amazing! This blog looks just like my old one!
It’s on a completely different topic but it has pretty much the same page layout and design.
Excellent choice of colors!
Thanks a lot for sharing this with all folks you really
recognise what you’re talking approximately! Bookmarked.
Kindly additionally discuss with my site =).
We may have a link exchange arrangement among us
Truly when someone doesn’t know then its up to other
visitors that they will assist, so here it happens.
Hi there to every body, it’s my first go to see of this webpage; this weblog carries remarkable and truly good data for readers.
Simply desire to say your article is as astounding. The clarity in your post is just great and i can assume you’re an expert on this subject. Fine with your permission let me to grab your feed to keep updated with forthcoming post. Thanks a million and please continue the gratifying work.
Wow! Thank you! I always needed to write on my website something like that. Can I implement a fragment of your post to my website?
Spot oon with this write-up, I seriously think this website needs much more attention. I’ll probably be bachk again to read through more, thanks for the info!
I visit daily some web sites and sites to read articles, except this website offers quality
based writing.
It’s going to be ending of mine day, but before finish I am reading
this impressive article to improve my knowledge.
I think the admin of this webb page is really working hard in favor of his web site,
as here every information is quality based stuff.
Pretty component to content. I simply stumbled upon your website and inn accession capital to claim that Iget in fact enjoyed aaccount your blog posts.
Anyway I’ll be subscribing for your feeds or even I success you get right
of emtry to persistently fast.
Hello friends, pleasant article and fastidious arguments
commennted here, I aam truly enjoying by these.
Howdy I am so excited I found your webpage, I really found you by accident, while I was looking on Askjeeve for something else,
Anyways I am here now and would just like to say thanks a lot for a fantastic post and a all round entertaining blog (I also love the theme/design), I don’t have
time to look over it all at the minute but I have
saved it and also added in your RSS feeds, so when I have time I
will be back to read a great deal more, Please do keep
up the superb jo.
Hi there! This is kind of off topic but I need some help from
an established blog. Is it tough to set up your own blog?
I’m not very techincal but I can figure things out
pretty quick. I’m thinking about making my own but I’m
not sure where to begin. Do you have any ideas or suggestions?
Appreciate it
Hey There. I found your weblog the usage of msn. This is an extremely neatly written article.
I’ll make sure to bookmark it and come back to learn extra of your helpful info.
Thanks for the post. I’ll definitely return.
I am really inspired along with your writing skills and also with the format on your
blog. Is this a paid topic or did you modify it yourself?
Either way stay up the excellent high quality writing, it’s rare to look a nice blog like this one today..
An impressive share! I’ve just forwarded this onto a co-worker who had been doing a little
research on this. And he actually ordered me dinner
because I found it for him… lol. So let me reword this….
Thanks for the meal!! But yeah, thanks for spending some time to
discuss this topic here on your blog.
Appreciate this post. Let me try it out.
I think this is among the most important information for me.
And i’m glad reading your article. But want to remark on some general things, The web site style is perfect, the articles is really great
: D. Good job, cheers
Good info and straight to the point. I don’t know if this is really the best place to ask but do you people have any thoughts on where to employ some professional writers? Thx ?
Its such as you learn my thoughts! You seem to understand a lot approximately this,
like you wrote the e book in it or something. I believe that you could do with a few p.c.
to force the message home a bit, but other than that, this is excellent blog.
A great read. I’ll certainly be back.
Very good website you have here but I was wanting to
know if you knew of any message boards that cover the same topics
discussed in this article? I’d really like to be a part of group where I can get comments from other
knowledgeable people that share the same interest.
If you have any suggestions, please let me know. Many thanks!
you aare really a good webmaster. Thhe site loading
speed is incredible. It kind of feels that you’re doing aany uniquie trick.
Also, The contents are masterpiece. you’ve performed a
fantastic job on this subject!
A round of applause for your blog.Thanks Again. Much obliged.
We stumbled over here from a different page and thought I might as well
check things out. I like what I see so i am just following
you. Look forward to going over your web page yet
again.
Hi would you mind sharing which blog platform you’re working with?
I’m looking to start my own blog soon but I’m having a difficult time making
a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and
style seems different then most blogs and I’m looking for
something completely unique. P.S My apologies for getting off-topic but I had to ask!
When some one searches for his essential thing,
thus he/she needs to be available that in detail, thus that thing is maintained over here.
Greetings! This is my first visit to your blog!
We are a group of volunteers and starting a new initiative in a community in the same niche.
Your blog provided us useful information to work on. You have done a extraordinary job!
whoah this weblog is fantastic i love reading your posts.
Keep up the great work! You know, many individuals are searching
round for this info, you can help them greatly.
you are really a good webmaster. The site loading velocity is incredible.
It seems that you’re doing any distinctive trick.
Moreover, The contents are masterwork. you’ve performed
a fantastic process on this subject!
Everything is very open with a precise explanation of the issues.
It was truly informative. Your site is very helpful.
Thank you for sharing!
Good info. Lucky me I recently found your website by accident (stumbleupon).
I have bookmarked iit for later!
You should be a part of a contest for one of the most useful websites on the net.
I most certainly will highly recommend this blog!
Hey there this is kinda of off topic but I was wanting to know if blogs use WYSIWYG
editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding knowledge so I wanted to get guidance from someone with experience.
Any help would be greatly appreciated!
Greetings! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly? My site
looks weird when viewing from my apple iphone.
I’m trying to find a theme or plugin that might be able to correct this issue.
If you have any recommendations, please share. Cheers!
My brother suggested I might like this blog. He was totally right.
This post truly made my day. You can not imagine simply how much time
I had spent for this information! Thanks!
Heya i am for the first time here. I found this board and I
find It really useful & it helped me out a lot. I hope to give something back and help others like
you helped me.
Hello there! Do you know if they make any plugins to assist with Search Engine Optimization? I’m
trying to get my blog to rank for some targeted keywords but I’m not seeing very
good success. If you know of any please share.
Thank you!
Amazing issues here. I am very happy to peer your post. Thank you so much and I am having a look ahead to touch you.
Will you please drop me a mail?
My brother suggested I might like this blog. He was
totally right. This post actually made my day. You can not imagine simply how much time I had
spent for this information! Thanks!
Helpful info. Fortunate me I found your website by chance, and I’m surprised why this coincidence didn’t came about in advance!
I bookmarked it.
Excellent post however , I was wanting to know if you could write a litte more on this topic? I’d be very grateful if you could elaborate a little bit further. Thanks!
Hi colleagues, its great paragraph on the topic of cultureand
fully explained, keep it up all the time.
I enjoy what you guys are up too. This kind of
clever work and coverage! Keep up the amazing works guys I’ve added you guys to our blogroll.
It is perfect time to make a few plans for the longer term
and it is time to be happy. I’ve learn this submit and if I may
I wish to suggest you few interesting things or tips. Maybe you could write subsequent articles regarding this article.
I desire to learn even more things about it!
I absolutely love your blog and find almost all of your post’s to
be precisely what I’m looking for. can you offer guest writers to write content
available for you? I wouldn’t mind publishing a post or elaborating on some of the subjects you write concerning here.
Again, awesome web log!
Its like you read my thoughts! You seem to know so much about this,
such as you wrote the guide in it or something. I believe that you just
can do with some p.c. to power the message home a bit, but other than that,
that is excellent blog. A fantastic read. I’ll certainly be back.
Greetings from Ohio! I’m bored to tears at work so I decided
to check out your blog on my iphone during lunch break.
I really like the information you provide here and can’t wait to
take a look when I get home. I’m surprised at how fast your
blog loaded on my mobile .. I’m not even using
WIFI, just 3G .. Anyhow, superb site!
I’m gone to tell my little brother, that he should also pay
a quick visit this website on regular basis to take
updated from latest news update.
My relatives every time say that I am killing
my time here at web, except I know I am getting knowledge daily by reading such pleasant posts.
I am curious to find out what blog system you happen to be working with?
I’m experiencing some minor security problems with my latest site and I’d like to find something more safe.
Do you have any solutions?
Hello there! This is my 1st comment here so I just wanted to give a quick shout out and say I really enjoy reading through your articles.
Can you recommend any other blogs/websites/forums that go
over the same topics? Many thanks!
Nice post. I was checking constantly this blog and I am impressed!
Extremely useful info specifically the last part 🙂 I
care for such information a lot. I was looking for this particular information for a long time.
Thank you and good luck.
After looking at a handful of the articles on your site, I seriously like your techniqueof writing a blog. I added it to my bookmark website list and will be checking back in the near future.Please visit my website as well and tell me what you think.
Great site you have got here.. It’s hard to find high quality writing like
yours these days. I seriously appreciate people like you!
Take care!!
Hey there! This is my first comment here so
I just wanted to give a quick shout out and tell you I really enjoy reading through your blog posts.
Can you suggest any other blogs/websites/forums that cover
the same topics? Thank you so much!
This article will assist the internet people for creating new blog or even a blog from start to end.
Incredible! This blog looks just like my old one! It’s
on a entirely different subject but it has pretty much the same layout and design. Great choice
of colors!
I read this paragraph completely on the topic of the resemblance of most recent and earlier technologies, it’s awesome
article.
This website was… how do I say it? Relevant!! Finally I have found something that helped
me. Thanks!
I savour, result in I discovered exactly what I was looking for.
You’ve ended my fouhr day long hunt! God Bless you man. Haave
a nice day. Bye
Hey There. I found your blog the usage of msn. That is an extremely neatly written article.
I’ll make sure to bookmark it and come back to read more of your
helpful info. Thanks for the post. I will certainly return.
I do not even know how I ended up here, but I thought this post was great.
I don’t know who you are but certainly you are going to a famous blogger if
you are not already 😉 Cheers!
I was curious if you ever thought of changing the page layout of your website?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people
could connect with it better. Youve got an awful lot
of text for only having one or 2 images. Maybe you could space it out better?
hi!,I love your writing so so much! percentage we communicate more approximately your article on AOL?
I need an expert on this house to resolve my problem.
Maybe that’s you! Looking forward to see you.
Hello! Do you use Twitter? I’d like to follow you if
that would be ok. I’m absolutely enjoying your blog
and look forward to new updates.
I always used to study post in news papers but now as I am a user of web therefore from now I am using net for content, thanks to web.
Greetings from Idaho! I’m bored to tears at work so I decided to browse your
website on my iphone during lunch break. I love the information you present here and can’t wait to take a look when I get home.
I’m surprised at how fast your blog loaded on my cell phone
.. I’m not even using WIFI, just 3G .. Anyhow, superb blog!
I read this post completely on the topic
of the difference of most up-to-date and previous technologies, it’s remarkable
article.
Valuable information. Lucky me I discovered your website accidentally, and I’m shocked why this twist of fate didn’t took place
in advance! I bookmarked it.
Hi to all, the contents present at this web page are really remarkable for people experience,
well, keep up the good work fellows.
This is really interesting, You are a very skilled blogger.
I’ve joined your feed and look forward to seeking more
of your magnificent post. Also, I have shared your website in my social
networks!
Article writing is also a excitement, if you know after that you can write
or else it is complex to write.
After looking at a number of the blog posts on your web site,
I truly appreciate your way of writing a blog.
I bookmarked it to my bookmark site list and will be checking back in the near future.
Please check out my web site too and tell me
your opinion.
No matter if some one searches for his necessary thing, thus he/she desires to be available that in detail, thus
that thing is maintained over here.
You have made some really good points there. I looked on the
web for more information about the issue and found most individuals will go along with your views on this website.
Hi, just wanted to mention, I loved this article. It was practical.
Keep on posting!
Hey! This is my 1st comment here so I just wanted to give a quick shout out and say I really enjoy reading your blog posts.
Can you suggest any other blogs/websites/forums
that cover the same subjects? Thank you!
Hey there would you mind letting me know which web host you’re using?
I’ve loaded your blog in 3 completely different internet browsers and I must say this blog loads a
lot quicker then most. Can you suggest a good hosting provider at a reasonable price?
Thank you, I appreciate it!
I’m not sure why but this blog is loading extremely slow for me.
Is anyone else having this issue or is it a problem on my end?
I’ll check back later on and see if the problem still exists.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added
I get several e-mails with the same comment. Is there any way you can remove people
from that service? Thanks a lot!
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get bought an nervousness
over that you wish be delivering the following. unwell unquestionably come further formerly again since
exactly the same nearly a lot often inside case you shield this hike.
I am truly grateful to the holder of this website who has shared
this fantastic article at here.
Asking questions are genuinely fastidious thing if you are not understanding something fully, but this paragraph
provides fastidious understanding yet.
constantly i used to read smaller posts which as well clear their motive, and that is also happening with this article which I am reading now.
Awesome site you have here but I was wondering if you knew of any user discussion forums that cover the same
topics discussed in this article? I’d really love to be a part
of online community where I can get feed-back from other experienced people
that share the same interest. If you have any recommendations, please
let me know. Thanks a lot!
whoah this blog is great i really like reading your articles.
Keep up the good work! You recognize, many persons are looking round for this information, you can help them greatly.
Excellent pieces. Keep posting such kind of info on your page.
Im really impressed by it.
Hi there, You’ve performed an incredible job. I will certainly digg it and in my view
suggest to my friends. I am sure they’ll be benefited from this web site.
My partner and I stumbled over here from a different web
address and thought I should check things out. I like whhat I see so now
i’m following you. Look forward to going over your web page for a second time.
Good article and right to the point. I don’t know if this is really the best place to ask but do you folks have any thoughts on where to employ some professional writers? Thanks in advance ?
Good blog you have here.. It’s hard to find high quality writing like yours nowadays.
I really appreciate people like you! Take care!!
I was curious if you ever thought of changing the layout of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so
people could connect with it better. Youve got an awful lot of
text for only having one or 2 pictures. Maybe you could space it out better?
Pretty section of content. I just stumbled upon your blog and in accession capital to assert that I acquire in fact enjoyed account
your blog posts. Any way I’ll be subscribing to your feeds and even I achievement you
access consistently rapidly.
I have read so many content about the blogger lovers except
this piece of writing is genuinely a good post, keep it up.
I am regular visitor, how are you everybody? This article posted at this site is
in fact nice.
I know this site presents quality depending articles or reviews
and extra information, is there any other site which offers such
stuff in quality?
I’m not that much of a online reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your site to come back
down the road. All the best
Hi, its fastidious post concerning media print, we all understand media is a impressive source of information.
Incredible points. Great arguments. Keep up the amazing work.
Ahaa, its nice conversation concerning this article here at this website,
I have read all that, so at this time me also commenting at
this place.
Excellent post. I was checking constantly this blog andI aam impressed! Very helpful info particularly the last part ? I care for suxh info much.I wass seeking tis certain information for a long time.Thank you and best of luck.
Thankfulness to my father who shared with me regarding this web site, this website is truly
amazing.
After looking over a few of the blog articles on your blog,
I hlnestly appreciate your technique of writing a blog.
I saved as a favorite it to my bookmark website list and will be checking back iin the nar future.
Take a look at my website tooo and tell me your opinion.
Wow, marvelous blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website
is magnificent, aas well ass the content!
I love your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to create my own blog and would like to know where u got this
from. many thanks
There is visibly a bunch to know about this. I assume you made certain good points in features also.
Youu really make it seem so esy with your presentation but I find this matter to bbereally something which I think I would never understand.It seems too complex and extremely broad forr me. I’m looking forward for your nextpost, I’ll try to get the hang of it!
I have interest in this, thanks.
Hello there! This post could not be written much better!
Going through this article reminds me of my previous roommate!
He constantly kept talking about this. I
am going to send this post to him. Pretty sure
he will have a very good read. I appreciate you for sharing!
Thanks for your posting. I also think that laptop computers have become more and more popular nowadays, and now in many cases are the only kind of computer utilized in a household. This is because at the same time actually becoming more and more inexpensive, their working power keeps growing to the point where they are as highly effective as personal computers from just a few years back.
I think what you published was very logical. However, think on this, what if you added a little information?
I ain’t suggesting your content isn’t good, but suppose you added a post title that makes
people want more? I mean Website Scraping Issues & The Applications – Relliks Systems is
kinda vanilla. You ought to look at Yahoo’s home page and see how they create
post headlines to grab people interested. You might add a related
video or a related pic or two to get readers interested
about everything’ve written. In my opinion, it could bring your website a little livelier.
thank you admin .
thank you bro
How long does a copyright last on newspaper articles?. . If a service copies newspapers articles and then posts it in a database on the Internet, is there also a copyright on the Internet content?.
thank you web site admin
Ok
Every weekend i used to pay a visit this website